
Although there is no official software release for MySQL 8.0 as of yet, most insiders believe that it’s likely to arrive sometime in 2018. In the meantime, Oracle has officially announced a tantalizing list of over two hundred new features! We recently covered Replication Performance Enhancements. Today’s blog will cover some of the other exciting enhancements we can expect when the production release of MySQL 8 hits the market.
New Database Roles
A role is a named collection of privileges that define what a user can and cannot do within a database. Roles play a vital part of database security by limiting who can connect to the server, access the database, or even access individual database objects and data.
Although prior to version 8, MySQL did provide a set of Privileges and Administrative Roles, the up-coming release will also support a set of flexible and properly architected roles, thus allowing DBAs to:
- Create and Drop Roles, Grant to Roles
- Grant Roles to Roles, Grant Roles to Users
- Limit Hosts that can use roles, Define Default Roles
- Decide what roles are applicable during a session
- And even visualize Roles with SQL function ROLES_GRAPHML()
Since each role packs multiple privileges, DBAs don’t have to remember exactly which permissions a user requires. Roles are also very easy to set up:
- Creating a new role:
CREATE ROLE ‘app_developer’, ‘app_read’, ‘app_write’;
- Assigning privileges to roles:
GRANT SELECT ON app_db.* TO ‘app_read’;
- Assigning the role to a user:
GRANT ‘app_read’ TO ‘read_user1’@’localhost’, ‘read_user2’@’localhost’;
Index Hiding, a.k.a “Invisible” Indexes
Hidden indexes are similar to disabled indexes, except that, in the case of the former, index information remain fully up to date and maintained by Data Manipulation Language (DML); it’s just invisible to the MySQL Optimizer. This feature is useful in hiding an index you suspect you don’t need, without actually dropping it. By marking an index as invisible, the MySQL optimizer will no longer use it. You can then monitor your server and query performance to decide whether to delete it or re-activate it, if it turns out that the index does provide improved performance.
This feature has two main uses:
Soft Delete
This was the situation described above where you don’t think an index is utilized any more. In this case rendering the index invisible is akin to throwing it in the recycle bin. In that state it’s still possible to restore it.
First you would render the index invisible:
ALTER TABLE Country ALTER INDEX c INVISIBLE;
You can revert it – i.e. make it visible again – if need be:
ALTER TABLE Country ALTER INDEX c VISIBLE;
If it is safe to drop the index:
ALTER TABLE Country DROP INDEX c;
Staged Rollout
Adding a new index can not only change existing execution plans, like all changes, it also introduces the risk of regression. That’s where your database becomes unstable due to multiple changes and additions that may not have been fully tested as a whole.
Invisible indexes allow you to stage all changes by putting the database in a “prepared” state.
You can add an index invisibly at an opportune time:
ALTER TABLE Country ADD INDEX c (Continent) INVISIBLE;
Then activate the index after testing the changes to everyone’s satisfaction:
ALTER TABLE Country ALTER INDEX c VISIBLE;
Improved JSON and Document Support
MySQL 5.7 introduced JSON support in order to compete with NoSQL databases that use JSON natively. That included the introduction of a JSON data type, virtual columns and a set of approximately 20 SQL functions that allow you to manipulate and search JSON data on the server side. MySQL 8 continues to build on 5.7’s foundation by improving performance, as well as by adding:
- functions to perform search operations on JSON values to extract data from them report whether data exists at a location within them, or report the path to data within them
- aggregation functions that let MySQL-native structured data and semi-structured JSON data be merged in a query
- document-store abilities
Searching JSON Data
Searching through JSON data is now easier thanks to the JSON_EXTRACT() function. It returns data from a JSON document (the first argument), selected from the parts of the document matched by subsequent path arguments. For example, here is a query the fetches the second data element from a JSON-formatted array:
mysql> SELECT JSON_EXTRACT('[10, 20, [30, 40]]', '$[1]');
+--------------------------------------------+
| JSON_EXTRACT('[10, 20, [30, 40]]', '$[1]') |
+--------------------------------------------+
| 20 |
+--------------------------------------------+
Aggregation functions
The MySQL 8.0 lab release added the JSON_ARRAYAGG() and JSON_OBJECTAGG() aggregation functions that can be utilized to combine data into JSON arrays/objects.
Consider the following table:
+------------------------+ | key | group | val | +------------------------+ | key1 | g1 | v1 | +------------------------+ | key2 | g2 | v1 | +------------------------+ | key3 | g3 | v2 | +------------------------+
The following query selects the keys as a JSON array:
mysql> SELECT JSON_ARRAYAGG(`key`) AS `keys` FROM t1; +--------------------------+ | keys | +--------------------------+ | [ "key1", | | "key2", | | "key3" ] | | | +--------------------------+
Document-store Abilities
Shortly after the JSON data type emerged came the MySQL Document Store feature. It was designed for developers who are not well versed in SQL but want to enjoy the many benefits that a relational database provides. In MySQL 8, reads and writes to the document store use transactions, so that changes to JSON data may be rolled back. Moreover, documents may be stored in the open GeoJSON format for geospatial data so that they can be indexed and searched according to proximity.
In order to function as a document store, MySQL employs the X Plugin and the MySQL Shell interface. It communicates with a MySQL using the X Protocol via the X DevAPI, a modern programming interface that provides support for established industry standard concepts such as CRUD operations. It is implemented in several programming languages, including Java, JavaScript, Node.JS, Python, and C++, with more on the way.
Say that you added the following JSON data to the document store:
{
GNP: .6,
IndepYear: 1967,
Name: "Sealand",
_id: "SEA",
demographics: {
LifeExpectancy: 79,
Population: 27
},
geography: {
Continent: "Europe",|
Region: "British Islands",
SurfaceArea: 193
}
}
You could then retrieve the document by ID (the _id field) using the find() method. Here is the call using the JavaScript shell:
mysql-js> db.countryinfo.find("_id = 'SEA'")
[
{
"GNP": 351182,
...
SurfaceArea: 193
}
}
]
Configuration Persistence
Changing configuration during MySQL runtime is commonly done using SET GLOBAL. This disadvantage of this technique is that the changes will not survive a server restart. As of MySQL 8, configuration changes applied via the SET PERSIST command will survive a MySQL server restart. For instance:
SET PERSIST max_connections = 500;
SET PERSIST works with any configuration variables, including offline_mode, read_only, etc…
One of the best things about SET PERSIST is that it does not require filesystem access, making it particularly useful when you don’t have system file access.
Unicode UTF-8 Encoding
With the precipitous rise of UTF-8 encoding in recent years, it has emerged as the dominating character encoding for the Web and modern applications. UTF-8’s dominance has been partially driven by “adopted words” from foreign languages, but more likely the main factor has been its support for emojis.
In a move that will do doubt make life easier for the vast majority of MySQL users, version 8 no  longer uses latin1 as the default encoding, to discourage new users from choosing a problematic legacy option. The recommended default character set for MySQL 8 is now utf8mb4, which is intended to be faster than the now-deprecated utf8mb3 character set and also to support more flexible collations and case sensitivity.
longer uses latin1 as the default encoding, to discourage new users from choosing a problematic legacy option. The recommended default character set for MySQL 8 is now utf8mb4, which is intended to be faster than the now-deprecated utf8mb3 character set and also to support more flexible collations and case sensitivity.
A collection of UTF-8 emoji

Common Table Expressions
Derived tables have existed in MySQL for a while now (since version 4.1 in fact). So what is a derived table, you may ask? A derived table is a subquery in the FROM clause (shown in bold font below):
SELECT … FROM (SELECT …) AS derived_table;
You could think of Common Table Expressions (CTEs) as improved derived tables – at least in their non-recursive form. CTEs can be recursive as well, bet that’s getting a bit ahead of ourselves.
The purpose of CTEs is to simplify the writing of complex SQL. You can always recognize them by the “With” keyword at the start of the SQL statement. For instance:
WITH t1 AS (SELECT * FROM tbl_a WHERE a='b') SELECT * FROM t1;
Here’s the same query rewritten using a derived table:
SELECT * FROM (SELECT * FROM tbl_a) AS t1 WHERE t1.a='b';
Recursive CTEs
A recursive CTE is a set of rows that is built iteratively like a programming loop. An initial set of rows is fed into the process, each time producing more rows until the process ceases to produce any additional rows. Syntactically, a recursive CTE refers to itself in a subquery; the “seed” SELECT is executed once to create the initial data subset, then, the recursive SELECT is repeatedly executed to return subsets of data until the complete result set is obtained.
Similar to Oracle’s CONNECT BY, Recursive CTEs are useful to dig in hierarchies such as parent/child and part/subpart relationships.
Recursive CTEs typically take this form:
WITH RECURSIVE cte_name AS ( SELECT ... <-- specifies initial set UNION ALL SELECT ... <-- specifies how to derive new rows )
Here’s a simple example that outputs 1 to 10:
WITH RECURSIVE qn AS ( SELECT 1 AS a UNION ALL SELECT 1+a FROM qn WHERE a<10 ) SELECT * FROM qn; +------+ | a | +------+ | 1 | | 2 | | 3 | | 4 | | 5 | | 6 | | 7 | | 8 | | 9 | | 10 | +------+
CTEs can also be utilized within SELECT, INSERT, UPDATE, DELETE statements. For example, taking our 1-to-10 example, we can name the column using the my_cte(n) syntax, and use the result of my_cte to create a table called “numbers”:
INSERT INTO numbers WITH RECURSIVE my_cte(n) AS ( SELECT 1 UNION ALL SELECT 1+n FROM my_cte WHERE n<10 ) SELECT * FROM my_cte;
Querying the numbers table confirms that it contains numbers from 1 to 10:
SELECT * FROM numbers; +------+ | n | +------+ | 1 | | 2 | | 3 | | 4 | | 5 | | 6 | | 7 | | 8 | | 9 | | 10 | +------+
Window Functions
An extremely useful feature, window functions have enjoyed support on many other database products for some time now. A window function performs a calculation across a set of rows that are related to the current row, similar to an aggregate function. However, unlike aggregate functions, a window function does not cause rows to become grouped into a single output row. This allows you to perform aggregate calculations across multiple rows while still having access to individual rows “in the vicinity” of the current row.
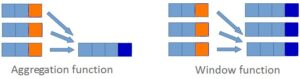
The currently supported functions include:
| Name | Description |
| CUME_DIST() | Cumulative distribution value |
| DENSE_RANK() | Rank of current row within its partition, without gaps |
| FIRST_VALUE() | Value of argument from the first row of window frame |
| LAG() | Value of argument from row lagging current row within partition |
| LAST_VALUE() | Value of argument from the last row of window frame |
| LEAD() | Value of argument from row leading current row within partition |
| NTH_VALUE() | Value of argument from N-th row of window frame |
| NTILE() | Bucket number of the current row within its partition. |
| PERCENT_RANK() | Percentage rank value |
| RANK() | Rank of current row within its partition, with gaps |
| ROW_NUMBER() | Number of current row within its partition |
For example, suppose we have a table that contains sales figures, we can aggregate total sales by country:
SELECT country, SUM(profit) AS country_profit FROM sales GROUP BY country ORDER BY country; +---------+----------------+ | country | country_profit | +---------+----------------+ | Finland | 1610 | | India | 1350 | | USA | 4575 | +---------+----------------+
By contrast, window operations do not collapse groups of query rows to a single output row. Instead, they produce a result for each row. Like the preceding queries, the following query uses SUM(), but this time as a window function:
SELECT year, country, product, profit,
SUM(profit) OVER() AS total_profit,
SUM(profit) OVER(PARTITION BY country) AS country_profit
FROM sales
ORDER BY country, year, product, profit;
+------+---------+------------+--------+--------------+----------------+
| year | country | product | profit | total_profit | country_profit |
+------+---------+------------+--------+--------------+----------------+
| 2000 | Finland | Computer | 1500 | 7535 | 1610 |
| 2000 | Finland | Phone | 100 | 7535 | 1610 |
| 2001 | Finland | Phone | 10 | 7535 | 1610 |
| 2000 | India | Calculator | 75 | 7535 | 1350 |
| 2000 | India | Calculator | 75 | 7535 | 1350 |
| 2000 | India | Computer | 1200 | 7535 | 1350 |
| 2000 | USA | Calculator | 75 | 7535 | 4575 |
| 2000 | USA | Computer | 1500 | 7535 | 4575 |
| 2001 | USA | Calculator | 50 | 7535 | 4575 |
| 2001 | USA | Computer | 1200 | 7535 | 4575 |
| 2001 | USA | Computer | 1500 | 7535 | 4575 |
| 2001 | USA | TV | 100 | 7535 | 4575 |
| 2001 | USA | TV | 150 | 7535 | 4575 |
+------+---------+------------+--------+--------------+----------------+
The main part of this query is SUM(profit) OVER (…), which are the window functions. PARTITION BY divides rows into groups while SUM() tallies the sales figures for the specified group (country).
Conclusion
From new database roles and index hiding to Recursive Common Table Expressions and Window Functions, MySQL 8 contains many long-awaited features and bug fixes. As to when it will be released, we can only guess at this point, since the production release was originally scheduled for October of 2017. There is one thing that we can say for sure: it will almost certainly have been worth the wait!


